【Part2】LINEBot × AWS で何か作ってみる【OCR編】
Part1 で作った LINEBot に、画像内の文章を OCR で抽出して返す機能を追加する。AWS が OCR の日本語に未対応なため、Google Cloud の Cloud Vision API を使って実装する。
前回までのあらすじ
前回はLINEBOTとAWSを連携して簡単なLINEBOTを作成しました。
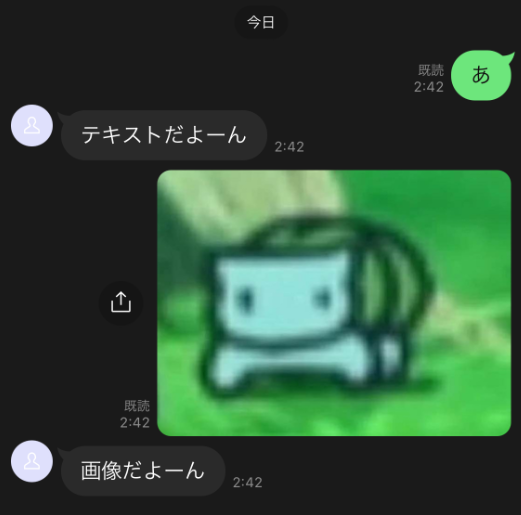
今回作るもの
ユーザから送信された画像に含まれる文章をOCR(光学文字認識)で抽出し、抽出結果を返却する機能を作成します。
AWS でOCRを扱えるサービスは、2024年3月時点では日本語対応していないのでGoogleCloudの「Cloud Vision API」というサービスを利用します。
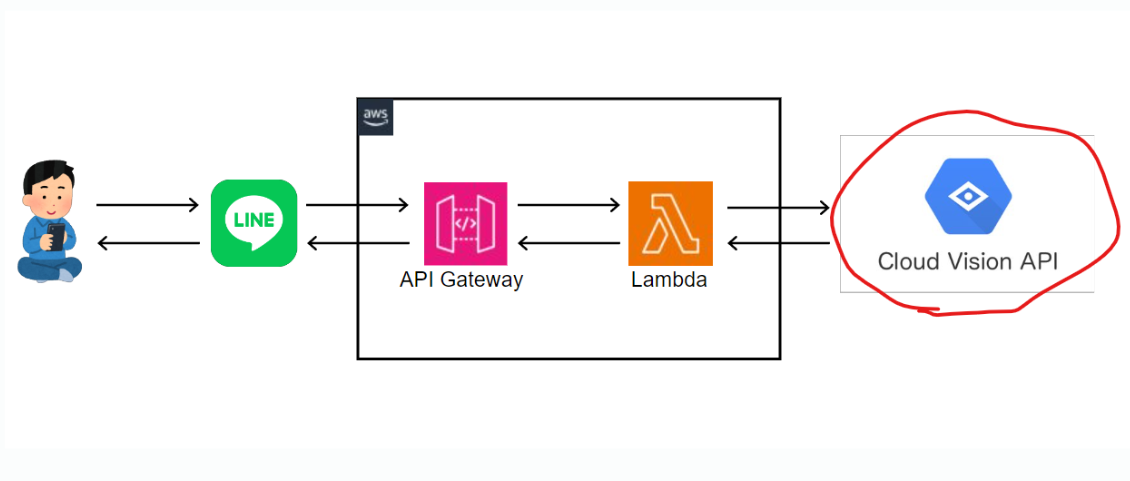
構成はこんな感じです。
Cloud Vision APIの登録
下記記事を参考にさせていただき設定を行いました。
https://dev.classmethod.jp/articles/google-cloud_vision-api/
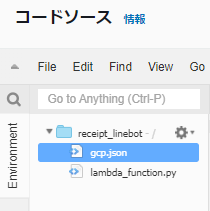
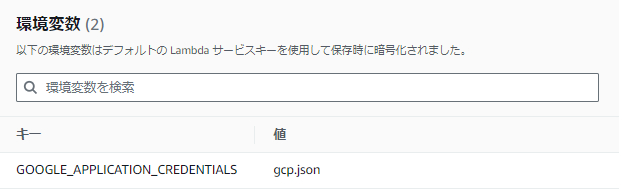
ここで作成したJSONをLambdaに配置し、環境変数「GOOGLE_APPLICATION_CREDENTIALS」を、認証情報を含む JSON ファイルのパスに設定します。
APIの認証はこれでOKみたいです。
Lambda Layerの作成
前回と同じくライブラリのインストールを行います。
google-cloud-visionだけ実行すると「protobufがない!」とエラーで怒られたのでprotobufを追加でインストールしています。何故欠落しているのかは分かりません。
$ pip install google-cloud-vision
$ pip install protobufLambda コードの作成
前回作成したプログラムの、画像がリクエストされた場合のコードブロックに、今回のプログラムを実装していきます。
import json
import os
from linebot import (LineBotApi, WebhookHandler)
from linebot.models import (MessageEvent, TextMessage, TextSendMessage)
from linebot.exceptions import (LineBotApiError, InvalidSignatureError)
from google.cloud import vision
import io
def lambda_handler(event, context):
body = json.loads(event['body'])
events = body['events']
line_bot_api = LineBotApi(channel_access_token=os.environ['LINE_TOKEN'])
# 複数リクエストを処理
for event in events:
if event['message']['type'] == 'text':
# テキストの場合
response_text = 'テキストだよーん'
continue
if event['message']['type'] == 'image':
# 画像の場合
# LINEから画像データを取得
message_id = event['message']['id']
message_content = line_bot_api.get_message_content(message_id)
# tmpディレクトリに書き込み
with open(f"/tmp/{message_id}.jpg", "wb") as f:
f.write(message_content.content)
# cloud visionクライアントをインスタンス化する
client = vision.ImageAnnotatorClient()
# tmpディレクトリから読み込み
with io.open(f"/tmp/{message_id}.jpg", 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
# Cloud Vision API 呼び出し
response = client.document_text_detection(
image=image,
image_context={'language_hints': ['ja']}
)
# Cloud Vision APIのレスポンスからテキストデータを抽出
ocr_output_text = ''
for page in response.full_text_annotation.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
for symbol in word.symbols:
if symbol.confidence > 0.1:
ocr_output_text += symbol.text
# 単語と単語の間にスペース
ocr_output_text += ' '
# 文と文の間に改行
ocr_output_text += '\n'
response_text = ocr_output_text
continue
else:
continue
# メッセージ送信
line_bot_api.reply_message(event['replyToken'], TextSendMessage(text=response_text))試してみる
いい感じに読み取ってくれています。
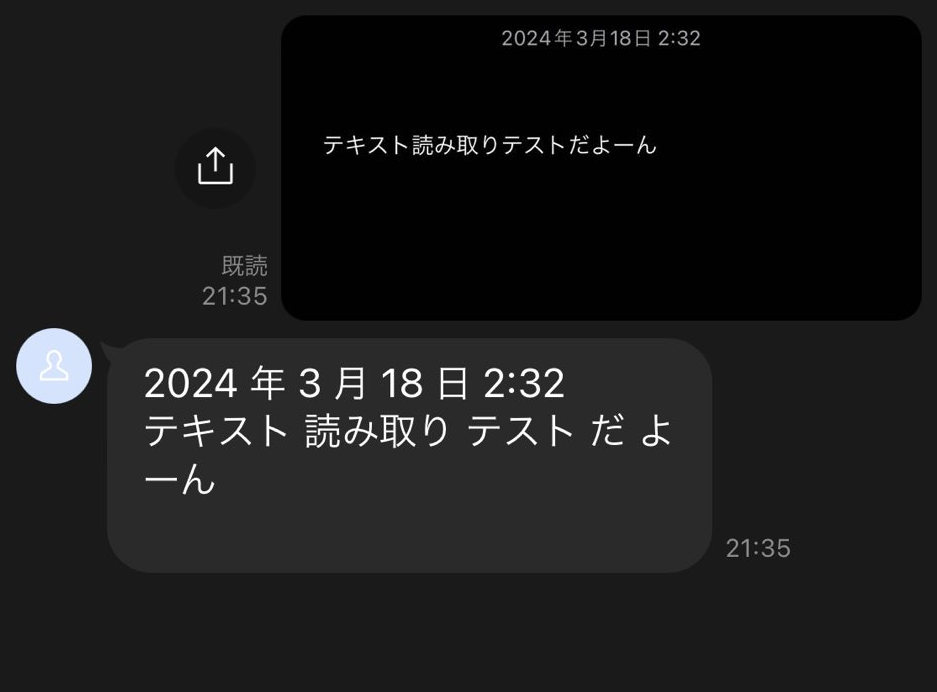
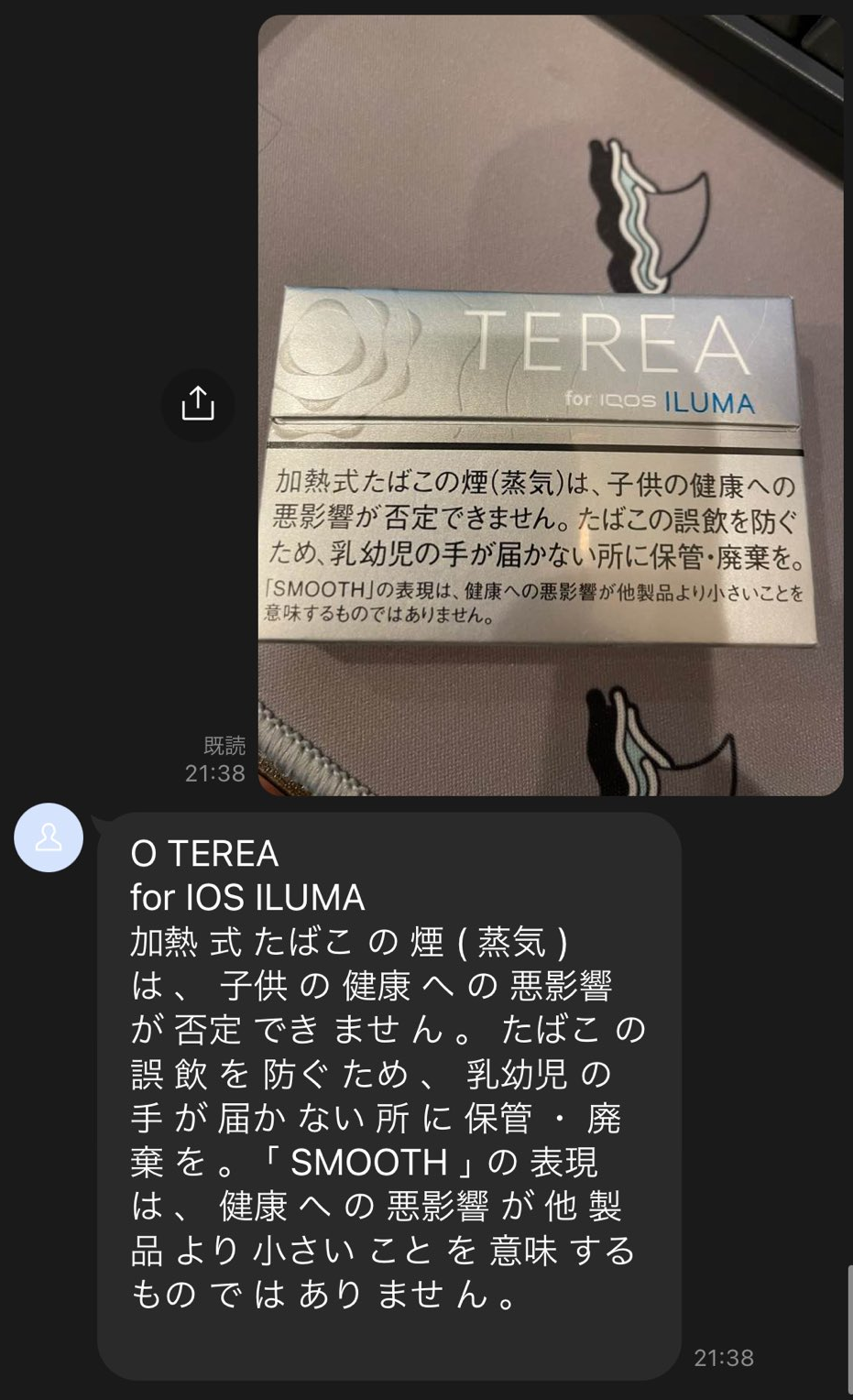
次回はこれに生成AIの機能を追加します。